
はじめに
Unitree Go2に標準で装備されているスピーカーとマイクを使用して、開発するサンプルを作成してみたいと思います。公式では、2025年6月時点では、オーディオ関連の開発用インターフェースが提供されておりません。なので、有志が作成されたWebRTC経由で接続可能なSDKを使用して実装をしてみます。
開発環境
今回は、公式のアプリで使用されている通信経路を用いて、操作をします。
なので、DockingStationが不要となるためEDU以外のAiRやPRO版でも開発が可能となります。
- Unitree Go2本体:Air/Pro/EDU ※ すべてのバージョンで可能
- 外部PC:Ubuntu 20.0.4 LTE ※ Windowsでも可能です
事前準備
- Unitree Go2を公式アプリからWi-Fi Modeで設定しておきます。
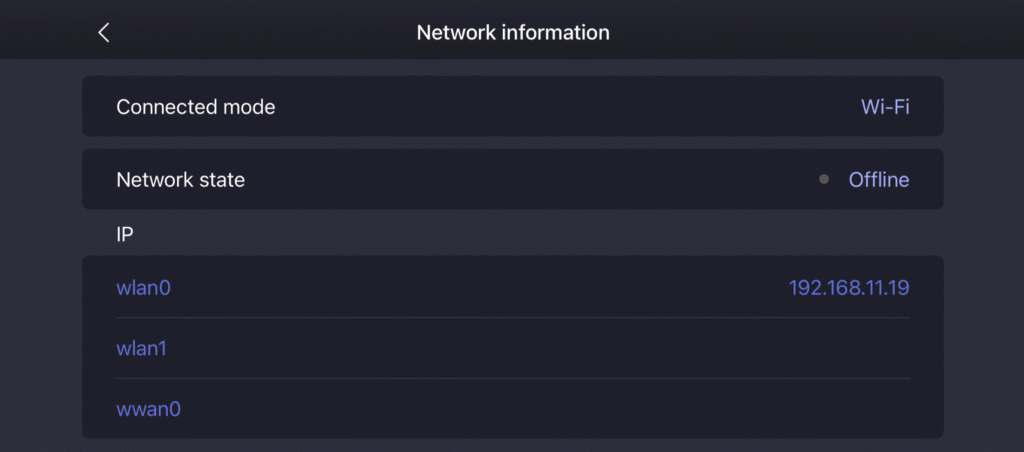
- 本体使用しているIPアドレスをアプリの設定から確認します。(Device>Data>Network informationのIP:wlan0)
- 外部PCを同じWifiに接続しておきます。
- アプリ落として、本体との通信を遮断しておきます。(本体の使用上、同時に通信できる端末の数が1台に限られるため)
SDKのインストール
Python環境とGitのレポジトリからアプリを取得するだけで利用が可能になります。
cd ~
sudo apt update
sudo apt install python3-pip
sudo apt install portaudio19-dev
git clone --recurse-submodules https://github.com/legion1581/go2_webrtc_connect.git
cd go2_webrtc_connect
pip install -e .
スピーカーの使用
サンプルを使用してGo2のスピーカーから任意のオーディオファイルを再生してみます。オーディオの再生は、以下の3種類のサンプルが用意されております。play_mp3は、動作が不安定で、なぜかwebrtc_audio_player.pyでアップロードをしておくとちゃんと動作する場合があります。今回は、webrtc_audio_playerの方の動作をご紹介します。(go2_webrtc_connect/examples/audio/mp3_player/webrtc_audio_player.py)
- play_mp3.py: mp3音源をwebrtcで送信し再生
- webrtc_audio_player.py: 音源を本体にアップロードし再生
- stream_radio.py: ストリーム音源を本体で再生
コードの中にIPを指定する部分があるので、そちらを事前準備で確認したIPに書き換えます。
conn = Go2WebRTCConnection(WebRTCConnectionMethod.LocalSTA, ip=”192.168.11.19″)
ファイルを書き換えたらコードを実行します。
1度目の実行で音声のアップロードが実行され、2度目の実行で音声が再生されます。
python3 webrtc_audio_player.py
🕒 WebRTC connection : 🟡 started (09:00:41)
Decoder set to: LibVoxelDecoder
🕒 Signaling State : 🟡 have-local-offer (09:00:41)
🕒 ICE Gathering State : 🟡 gathering (09:00:41)
🕒 ICE Gathering State : 🟢 complete (09:00:41)
ERROR:root:An error occurred: HTTPConnectionPool(host='192.168.11.19', port=8081): Max retries exceeded with url: /offer (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7fe84a42c730>: Failed to establish a new connection: [Errno 111] Connection refused'))
ERROR:root:An error occurred with the old method: Failed to receive SDP Answer: No response
🕒 ICE Connection State : 🔵 checking (09:00:42)
🕒 Peer Connection State : 🔵 connecting (09:00:42)
🕒 Signaling State : 🟢 stable (09:00:42)
🕒 ICE Connection State : 🟢 completed (09:00:42)
🕒 Peer Connection State : 🟢 connected (09:00:42)
🕒 Data Channel Verification: ✅ OK (09:00:42)
[{'UNIQUE_ID': 'ee9ff303-dfa0-4dc0-a459-54c30edc31c6', 'CUSTOM_NAME': 'dog-barking', 'ADD_TIME': 1750564220117}, {'UNIQUE_ID': 'ceaa9e31-d1cd-4fbc-b983-2fd9e0589d43', 'CUSTOM_NAME': 'sample', 'ADD_TIME': 1750563978309}]
Audio file sample already exists, skipping upload
Starting audio playback of file: ceaa9e31-d1cd-4fbc-b983-2fd9e0589d43
🕒 Signaling State : ⚫ closed (09:00:42)
本体から犬の鳴き声が聞こえたら成功となります。
本体からマイク入力の取得
サンプルは2種類用意が用意されており、5秒間の音声入力を保存する(save_audio_to_file.py)とライブでオーディオファイルを取得する(live_recv_audio.py)があります。
今回はsave_audio_to_file.pyの方で動作を確認しました。先程と同様にコードのIPの部分を変更しファイルを実行します。
python save_audio_to_file.py
実行が完了すると、レポジトリのルートに「output.wav」というファイルが出力されます。こちらが実際の音声ファイルです。本体のファンの音が大きくかなり雑音がのっています。
Whisperを使用して音声認識ができるかを検証しました。
pip install -U openai-whisper
import whisper
# モデルをロード
model = whisper.load_model("base")
# 認識実行
result = model.transcribe("output.wav", language="ja")
# 結果出力
print("🗣 認識結果:")
print(result["text"])
「こんにちはーこんにちはー」の音声認識をモデル別で識別した結果になります。ノイズに強いwhisperでもbaseレベルだと簡単な認識でも難しそうです。
リアルタイム性を求めるのであれば、GPU搭載のPCでmedium以上で実装するのが良さそうです。
🗣 認識結果:
どうも、チュアー。どうもチュアー。
おわりに
二次開発ができないバージョンでも開発ができる素晴らしいライブラリですが、非公式であるため動作が不安定なのがきになりました。外付けのノイズキャンセリング対応スピーカーマイクを使用するのが良さそうです。